10k+ Downloads5.0 Stars


The Ultimate Library for
Managing PDF Documents
MuPDF is the fast & powerful solution for managing PDF and other document formats.




Trusted by companies across the globe
New Product
A Complete PDF Viewer,
Embedded in Minutes
Built on the MuPDF engine to ensure unmatched speed, performance, and stability.
Try It Now
Try PyMuPDF for
Office Documents and LLM

PyMuPDF Pro for Office Documents
PyMuPDF Pro supports a wide range of Office file formats, including DOC/DOCX, PPT/PPTX, XLS/XLSX, as well as HWP and HWPX, the widely used formats for Korean word processing.
Try PyMuPDF Pro Free for 60 Days
Get a Trial Key
PyMuPDF4LLM for RAG Integrations
PyMuPDF integrates seamlessly with LangChain, Llamaparse and more! Prepare your data for RAG solutions and give your LLM the data that your users can trust.
Built to Handle Every
PDF Task
MuPDF gives you full control over PDF documents — view, edit, extract, sign, and more. All in one fast, embeddable SDK.

Extract Content from PDF
Pull text, images, metadata, and structured content from PDF files with precision.

Render Documents
High-quality rendering for PDFs and other document formats — fast and pixel-perfect.

Embed PDF Documents
Embed a smooth, customizable document viewer into your webpage or app.

Redact Sensitive Content
Permanently remove sensitive content from PDFs with pixel and text-level redaction.

Create New PDF Documents
Create new PDF files with the contents created from one or more input files.

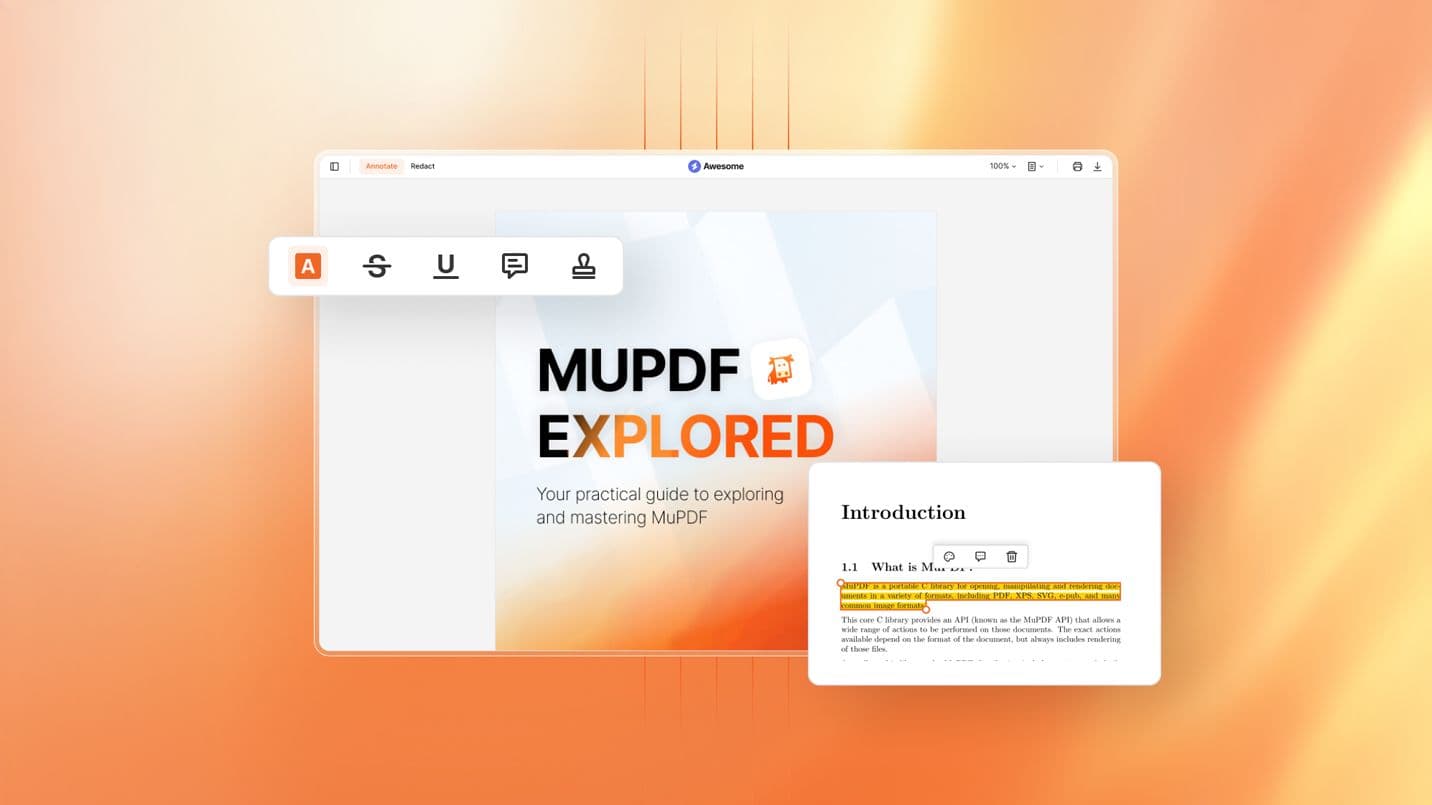
Annotate PDFs with Markups
Add highlights, comments, stamps, shapes, and other markups to any page.

Parse PDF Documents
Access low-level PDF objects and layout.

Split PDFs into Smaller Documents
Break large PDFs into smaller files based on page range, bookmarks, or rules.

Convert from or to PDF Format
Transform files between PDF and formats like SVG, PNG, and more.

Merge Multiple PDFs
Combine multiple PDF files or pages into a single, unified document.

Digitally Sign PDFs
Add digital signatures with cryptographic support for document verification.

Compress PDFs
Compress and clean up PDFs to reduce file size without losing quality.
Document Formats
MuPDF is the most versatile player in our category when it comes to document formats. Below is a list of our supported input/output file types.
Input
- ePUB
- PNG, JPG, BMP, TIFF, GIF
- SVG
- PNM/PAM
- CBZ
- XPS
Output
- Text
- HTML
- PostScript
- PCL5/PCLM (Mopria)
- PWG/CUPS
- Proofing
- PNG, SVG
- PNM/PAM
Get Licensed to Build
without Limits
Unlock the full potential of MuPDF without open-source restrictions.
 No source code disclosure
No source code disclosure- Full modification and redistribution rights
- Get access to technical support
- Everything you need to build and ship with confidence